An Introduction to My PhD Research
An Introduction to My PhD Research
This is the start of a series of journal entries about my recently completed dissertation titled Enabling Scientific Data on the Web at the School of Informatics, University of Edinburgh . As I wait to defend my dissertation (July?), I’m going to try to explain what I’ve been up to these past four years. My hope is that not only will people understand what I’ve been doing, but also it will help me find new ways of explaining it other than a rather long document that few will actually read cover-to-cover.
Empowering Scientific Data on the Web
The casual observer may take issue with this statement. As humans, we can search and navigate to all kinds of scientific content on the Web, gain knowledge and understanding from it, and then derive answers. If this is the case, how can we say that science hasn’t been successful on the Web?
The simple answer is that these are mostly the results of science and not the act of processing scientific data within the Web for the purpose of scientific endeavors. While I’m not trying to put the wrong spin on this, much of what is available is for consumption by people and falls into two broad categories:
- Information silos that have been carefully crafted, derived from years of effort, the result of well-funded entities, for an often singular purpose of communicating or collaborating over information (e.g., GalaxyZoo ).
- Information refined, produced, and published for consumption by a particular audience (e.g., Wikipedia — ).
These kinds of information or activies on the Web are very important resources for communicating about science. They provide the ability for non-scientists and scientists to interact with scientific data, find resources for answering questions, and help education generations of people interested in science. Yet, producing these resources requires both sufficiently well-funded entities and people with the perseverance to complete the task.
Meanwhile, hiding in plain sight, are vast resources that are the artifacts of scientific endeavors. There are plenty of scientific data sets accessible from the Web, from scientific sources, agencies, and governments, that are available for download. For example, the (an astronomical data set) is 15.7 TB of images, 26.8 TB of other data, and 18 TB of catalogs. In fact, there are many massive repositories of astronomical, genome, climate, and other data that are available, possibly via the Web. So, aren’t we done?
The answer is that by simply putting up an archive (a zip file), possibly massive in size, of “data” whose format isn’t one your browser understands doesn’t really make the data itself on the Web. The data is accessible from the Web by those wishing to download it, find tools that can process the formats, and then use that data for scientific endeavors. Yet, the time and effort necessary to complete all those tasks may be more than one desires and so the data may go unnoticed or unprocessed.
We want to enable some, if not all, of such processes to be handled on the Web and within the Open Web Platform. The goal is to ease development of processing of scientific information so that deriving new processes is easier. It is a big goal and not all of it is probably possible at this moment. Yet, how far can we push the Open Web Platform to enable scientific data to be processed as a first-class citizen?
This brings us to my hypothesis:
Scientific Data is Often Tabular
In an attempt to quantify the kinds of scientific data that may be out there, I examined the US Government’s repository for open data provided at data.gov . I specifically looked at the metadata for 441,360 entries for geospatial data sources. The format of the data for each of these entries is shown below:
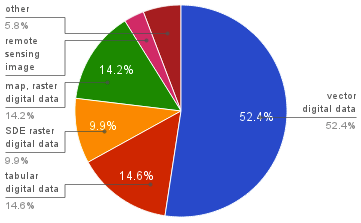
Geospatial Data Formats
Of these formats, consider the top two categories of “vector digital data” and “tabular digital data” . Many of the vector digital data formats, the most common of which is ESRI ShapeFiles, contain some amount of tabular annotations. A safe assumption is that some large portion of the 67% (52.4% + 14.6%) of the data is tabular or contains tabular data.
There are plenty of more sources other than from data.gov to consider. For example, the National Oceanic Atmospheric Administration (NOAA) provides vast sensor networks (e.g., weather, climate, ocean, etc.) that feed into its various agencies (e.g., National Weather Service) as well as the public. The much of this data is tabular time-series data.
Let’s also not forget the astronomers as they love to share data. The various standards for services provided by the International Virtual Observatory Alliance (IVOA) are centered around sharing data via something called . As you might guess, it is a standard way of exchanging tabular data for astronomical services.
Scientists like tables of data. They make lots of tables of data. They share tables of data. They use tables of data and compute more tables of data.
What Next?
What we need is a good way to exchange tabular data, as the baseline lingua franca of scientists, that properly conveys what the table represents and completely defines the semantics for each column of data. We need a common mechanism for encoding information in a format that is directly processable by the Open Web Platform. We also need a way to encode semantics.
We also need a way to access this data in portions with a minimum amount of complexity so that a browser can process the data and do useful work. Massive archives are not accessible ways to allow people to load, process, and experiment with data. We need a mechanism that fits within the Web and the protocols it uses.
Finally, it isn’t just enough to label data as “time” , “temperature” , or “location” . We need to ground measurements in both their reference measurement systems and the methodology used to collect them. Labels need to be unambiguous so that “temperature” becomes “air temperature measured over land at a specific elevation ” to promote interoperability where intersections exist and prevent bad assumptions that lead to bad science.
Interestingly, to start down this path, we need to go back in time a bit and look at what the astronomers were doing in the mid-to-late 1990’s as early adopters of the Web as a mechanism for sharing data. We’ll see how they embraced XML, rejected complicated web services, and provided immediate and direct value to their users. We’ll also get to examine a few short-comings of their approach and see where we can go from there.